
Hallo zusammen,
ich stehe total auf dem Schlauch. Hab schon länger mit statistischer Auswertung nichts mehr zu tun aber muss nun eine Studie auswerten. Es geht um folgendes: Es wurden n=107 Teilnehmern 2 Fragen gestellt, die ähnlich wie beim Schulnotensystem bewertet werden sollen (auf einer Skala von 1 = gut und 7= schlecht). Die Fragen wurde in ausgeglichener Reihenfolge gestellt. Wenn Frage A zuerst gestellt wurde war M = 5,4 und SD = 1,37 und wenn zuletzt war M = 5,38 mit SD = 1,7. Wenn Frage B zuerst gestellt wurde war M = 3,58 mit SD = 1,8 und falls zuletzt war M = 3,72 mit SD =1,63. Der Unterschied in Frage B ist nun signifikant mit (paired t(105) = 5,89 mit p < .001). Den p-Wert verstehe ich und auch das t über dem kritischen Wert liegt, also die Nullhypothese verworfen wird. Aber wie wurde jetzt t berechnet? Ich komme irgendwie nicht auf den Wert von 5,89. Und warum ist t(105)? Für Freiheitsgrade gilt doch n-1, oder? Wäre doch hier dann 106. Ich muss auch die Effektstärke Cohen's d selber berechnen. Welche Standardabweichung setze ich im Nenner ein?
Ich wäre sehr dankbar, wenn mir das alles kurz einer erklären könnte. Vielen Dank im voraus!
Gruß
Tom
Beispiel abhängiger T-Test und Effektgröße
Thema bewerten:  • 2 Beiträge
• Seite 1 von 1
• 2 Beiträge
• Seite 1 von 1
Beispiel abhängiger T-Test und Effektgröße
![]() von Tom89 » Sa 21. Sep 2013, 10:09
von Tom89 » Sa 21. Sep 2013, 10:09
- Tom89
- Einmal-Poster

- Beiträge: 1
- Registriert: Fr 20. Sep 2013, 22:24
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Beispiel abhängiger T-Test und Effektgröße
![]() von Sven » So 29. Sep 2013, 10:11
von Sven » So 29. Sep 2013, 10:11
Die Teststatistik für den t-Test für abhängige Stichproben ermittelt man wie folgt.
Es seien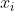 sowie
sowie 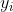 die Werte beider Stichproben und
die Werte beider Stichproben und 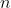 die Anzahl der gemeinsamen Beobachtungen.
die Anzahl der gemeinsamen Beobachtungen.
1) Im ersten Schritt ermittelt man die Differenzen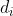 zwischen zwei Zusammengehörigen Beobachtungen:
zwischen zwei Zusammengehörigen Beobachtungen:
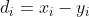
2) Weiterhin benötigt man die mittlere Differenz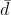 :
:
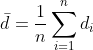
3) DIe Schätzung der Standardabweichung der Differenzen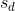 erhält man folgendermaßen:
erhält man folgendermaßen:
^2})
4) Nun hat man alle Werte um die Teststatistik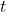 zu berechnen:
zu berechnen:
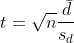
Der ermittelte t-Wert hat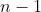 Freiheitsgrade, in diesem Beispiel also tatsächlich 106.
Freiheitsgrade, in diesem Beispiel also tatsächlich 106.
Es seien
1) Im ersten Schritt ermittelt man die Differenzen
2) Weiterhin benötigt man die mittlere Differenz
3) DIe Schätzung der Standardabweichung der Differenzen
4) Nun hat man alle Werte um die Teststatistik
Der ermittelte t-Wert hat
- Sven
- Einmal-Poster
- Beiträge: 1
- Registriert: Sa 28. Sep 2013, 21:40
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Thema bewerten: • 2 Beiträge
• Seite 1 von 1
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 0 Gäste