ich habe ein Problem das hier wahrscheinlich nicht zum ersten Mal diskutiert wird, brauche aber eine Antwort auf meinen ganz spezifischen Fall und meine dazugehörigen Fragen..
Ich schreibe meine Bachelorarbeit im Produktmarketing und habe eine Choice Based Conjoint Analysis durchgeführt. Für die Auswertung habe ich eine Cox-Regression durchgeführt und habe jetzt bei manchen Werten eine Signifikanz von .000, bei anderen aber <.9. Ich bin kein Statistiker, sondern Wirtschaftsingenieur und weiß jetzt nicht ob ich die Ergebnisse überhaupt irgendwie für eine Interpretation verwenden kann.
Hier noch ein paar Randdaten:
- Stichprobengröße 14
- Choice Sets pro Probant 12
- 4 Attribute mit je 3 Ausprägungen, eine "none" Option
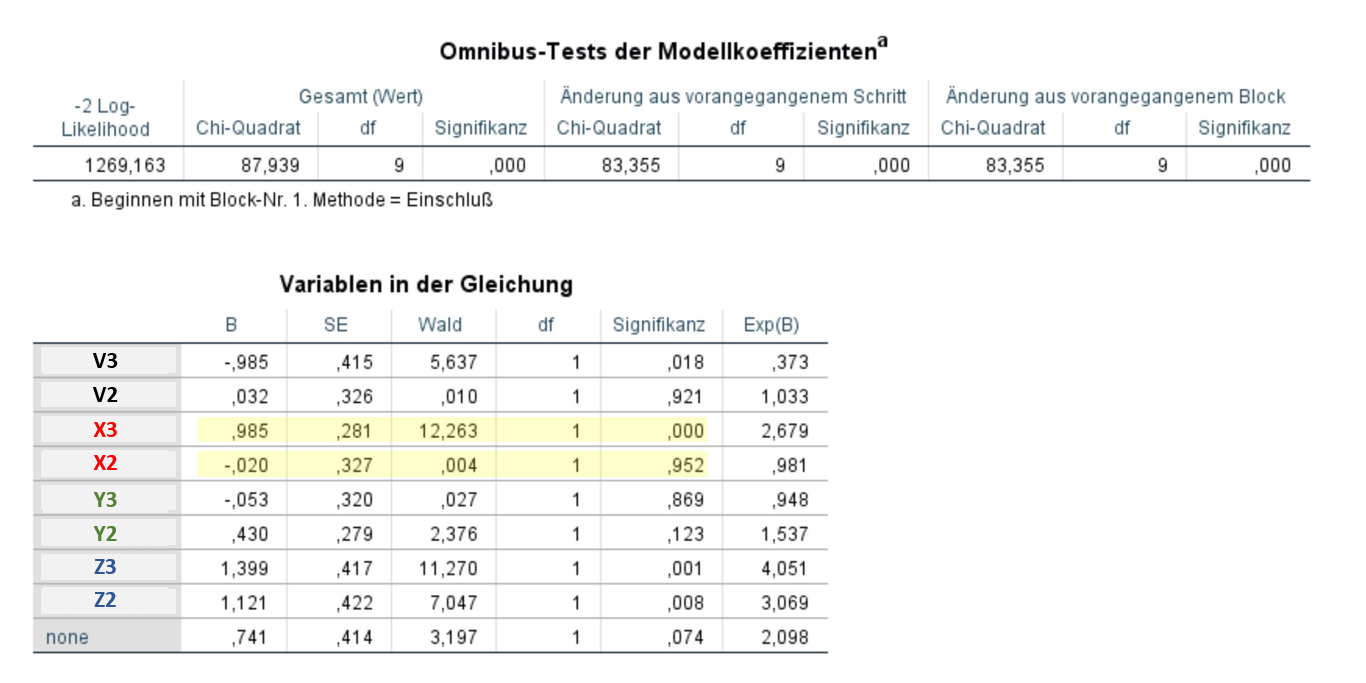
Für die Analyse bin ich nach der Anleitung von Backhaus (Fortgeschrittene Multivariate Analsemethoden) vorgegangen. Jedes Attribut hat in der Auswertung eine Basis, der B = 0 darstellt und nicht in der Ausgabe zu sehen ist. Die Attribute habe ich in der Ausgabe, von der ich einen Screenshot hochgeladen hab, mit Buchstaben und Nummern substituiert, da ich in einem Unternehmen schreibe und die genauen Attribute der Geheimhaltung unterliegen.
Für meine Studie ist das Nutzen-delta von "X3" auf "X2" (siehe Bild) der Interessantest Wert. Dadurch, dass "X2" in keiner weise statistisch relevant ist kann ich die Nutzenwerte in Spalte "B" ja nicht miteinander vergleichen, da die Wahrscheinlichkeit fast 100% ist dass bei „2“ eine Nullhypothese verworfen wird obwohl es eine ist.
Kann ich stattdessen argumentieren, dass die Kunden "X3" ganz bewusst ausgewählt haben (weil Sig = .000), bei "X2" allerdings davon ausgegangen werden kann, dass es rein zufällig gewählt wurde weil kein signifikanter Nutzen dargestellt werden kann? Könnte ich dann argumentieren, dass es sein kann, dass „X2“ "einfach in einem Stimulus mit dabei" war welches der Kunde wegen den anderen Attributen gewählt hat? Meine Schlussfolgerung wäre dann, dass zwar nicht quantitativ bewiesen werden kann, dass "X3" den Kunden einen höheren Nutzen liefert als "X2", aber qualitativ gezeigt werden kann, dass Kunden "X3" ganz bewusst wählen, während sie Produkte mit "X2" eher zufällig wählen, und deshalb davon auszugehen ist, dass "X3" einen deutlich höheren Nutzen liefer als "X2"?
Meine Fragen sind jetzt die folgenden:
1. Kann ich die genannte Schlussfolgerung so argumentieren oder ist das falsch?
2. Wie sieht das dann im Vergleich zum Basiswert aus, woher weiß ich ob das Attribut gezeilt gewählt wurde oder nicht? Davon würde ja auch das B von „X3“ abhängen.
3. Kann ich die statistisch signifikanten Werte (V3, X3, Z3, Z2) über ihre B-Werte miteinander vergleichen, auch wenn die anderen Ausprägungen teilweise nicht signifikant sind?
4. Kann ich bei den restlichen Attributen (auch den nicht-signifikanten) dann nur sagen, dass Schlussfolgerung aus 1. Zutrifft und es den Kunden Wurscht ist ob ein Produkt jetzt „Y2“ oder Y3“ hat?
5. Ist meine Stichprobe einfach zu klein für eine CBCA? (Vergleichbare Studien hatten oft deutlich mehr Teilnehmer, allerdings konnte ich nicht mehr durchführen, da das die CBCA nur Teil eines Tiefeninterviews war)
Ich danke euch im Voraus!
Liebe Grüße
Janik
Hier der Link zu dem Screenshot. Kann es leider nicht direkt hier hochladen?!