Hey Patrick,
ich finde Deine Darstellung verwirrend.
patrickB hat geschrieben:a: μ = 1, σ = 0.05 (1 + 0.05 * randn(25,1))
B: μ = 0.04, σ = 0.0005 (0.04 + 0.0005 * randn(25,1))
c: μ = 0.6 σ = 0.05 (0.6 + 0.05 * randn(25,1))
Die Funktionsbezeichnung
randn kann auf Matlab, hindeuten, kann auf Python hindeuten und kann Pseudocode sein. Wenn du auf ein spezielles System eingehen willst, solltest Du das auch spezifizieren.
Mit Hilfe der drei Variablen berechne ich dann die zu untersuchende Basis der Daten mittels d1=a+b+c.
Was verstehst Du unter einer "zu unterzuchenden Basis der Daten"? Ist die "Basis der Daten" das gleiche wie die "Daten"?
Das ganze 25 mal.
Der Code oder Pseudocode oben produziert pro Aufruf 25 Zufallszahlentripel. Willst Du 25 Mal den Code aufrufen, also
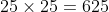
Zahlentripel berechnen oder beschreibst Du jetzt nur ein weiters Mal, dass Du 25 Zahlentripel haben willst?
Dann erzeuge ich mir noch einmal Daten (N = 5, 10, 15 und 25), diese werden aber zusätzlich noch einmal verrauscht (d2 = a+b+c + rauschen).
Es ist rätselhaft, dass Du uns für
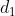
die genauen Mittelwerte und Standardabweichungen nennst, die Natur des Rauschens aber so unspezifisch lässt. Warum gibst Du uns Rätsel bezüglich des Vorgehens auf?
Ich möchte jetzt feststellen, ob 5, 10, 15 oder 25 Werte gemessen werden müssen, um eine ähnlichen Mittelwert bzw. eine ähnliche Verteilung der Werte zu erhalten wie in d1.
Wie PonderStibbons schon geschrieben hat ist "ähnlich" kein statistischer und kein mathematischer Begriff. Wenn dieser Begriff/diese Begriffe zum Kern der Fragestellung werden, müssen sie präzise Definitionen bekommen.
(Im Forum kann ich direkt nichts hochladen, da erhalte ich: "Das Kontingent für Dateianhänge ist bereits vollständig ausgenutzt.")
Ein altes Problem. Auch wenn die Forenadministration sich seit Jahren nicht darum schert, dass immer wieder Leute ihre Zeit damit verplempern, kann ich Dich nur bitten, Dich bei einem der beiden Administratoren zu beschweren. Vielleicht höhlt ja steter Tropfen den Stein.
Im Boxplot sieht es für mich erst mal so aus, als ob N = 5 und 10 nicht ausreichend sind, 15 und 25 aber schon.
Wie könnte ich das jetzt statistisch korrekt beschreiben?
Eine präzise Beschreibung, was für Dich wie aussieht, können wir nicht liefern.
Untersuchung 1: Unterscheiden sich N 5, 10, 15 und 25 signifikant? -> Varianzanalyse (unbalanciert)?
Ich glaube nicht, dass eine Varianzanalyse das widerspiegelt, was Du mit "gleich aussehen" meinst.
Untersuchung 2: Reichen N Messung aus? Da würde ich jedes d2 (N = 5, 10, 15 und 25) mit d1 vergleichen. Alle Daten sind jedes mal zufällig generiert -> unabhängig, weil zufällige Zahlen? Oder ist es doch abhängig, weil die Zufallszahlen aus einem bestimmten Bereich (siehe μ und σ) erzeugt werden?
Das sind unabhängige Stichproben aus identischen Verteilungen.
Sei
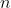
eine große Zahl und
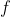
eine Funktion die eine 1 zurück gibt, wenn eine Zahlenreihe ähnlich wie
verteilt ist und eine 0 zurück gibt, wenn die Zahlenreihe zu unähnlich zu
ist.
Dann kannst Du in einer Schleife
mal eine 5er Stichprobe
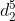
und ein
ziehen und aufaddieren, wie oft die Funktion 1 wird, also
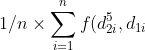)
ist.
Analog dann
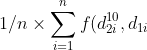)
und
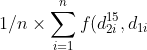)
usw.
Egal ob Matlab oder Python, ein fünfstelliges
sollte schneller zu rechnen sein, als Du Dir einen Kaffee kochen kannst. Mach das mehrmals, und wenn die Ergebnisse zu sehr divergieren, dann nimm halt ein sechsstelliges
.
HTH,
Bernhard


