Hallo ich bin neu hier und hoffe das meine Frage nicht schon gestellt wurde. Ich habe mich hier schon etwas umgesehen aber leider keine befriedigende Antwort gefunden. Ich bin leider kein Statistik Profi und habe eher Erfahrung mit Regressionen als anderen statistischen Tests, muss mich im Rahmen meiner Masterarbeit jedoch mit Textanalysemethoden.
Folgendes Problem: Ich habe Texte von 2 verschiedenen Quellen und muss diese auf bestimmte Argumente überprüfen mein Datensatz hat folgende Form:
Eine Variable
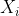
mit den Ausprägungen
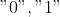
soll auf Unabhängigkeit mit der Variablen
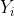
mit Ausprägungen
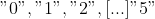
getestet werden.
Soweit so gut. Nach Aufbereitung musste ich jedoch feststellen dass in speziell definierbaren Clustern (Argumente innerhalb ein und desselben Artikels) Abhängikeitsstrukturen zwischen den Ausprägungen von
vorhanden sind. Diese äußern sich in schwachen (aber teilweise signifikanten paarweisen Korrelationen der Ausprägungen (zwischen
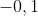
und
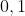
). Ich gehe davon aus das diese meine Resultate nicht besonders beeinflussen sollten, deshalb Fände ich es super wenn es in diesem Falle irgendeine Möglichkeit gäbe für diese Autokorrelation (ähnlich wie zB Newey West für Regressionen) zu korrigieren ohne den Test komplett über Board zu werfen. Als Alternative würde ich natürlich auch einen anderen Test nehmen der mit dieser Korrelation gut umgehen kann, kenne mich jedoch da zu wenig aus mit den Verfahren.
Kann mit jemand weiterhelfen?
Danke schonmal für eure Antworten



