klaus82 hat geschrieben:Irgendwie erscheint das jetzt unbrauchbarer, ich habe es auch mit log-log-komplementär versucht. Dann schnellt Nagelkerke auf 8 hoch, aber die Variable Smog erfüllt überhaupt keine Signifikanzen mehr und wäre als erklärende Variable auszuschließen.
Wie kann das denn passieren? Die pseudo-
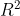
können nur zwischen 0 und 1 liegen!
klaus82 hat geschrieben:Ausserdem habe ich noch einen Versuch gemacht, indem ich nur
Was hast du dort versucht?
klaus82 hat geschrieben:Ich verstehe wirklich nicht, warum ein umkodieren soviel ändert. Es geht doch um Wahrscheinlichkeiten in Kategorien zu landen. Werden die erklärenden Variablen vielleicht wegen der Kodierung fälschlicherweise als ordinal skalierte Variablen erkannt?
Wie du an den Outputs erkennen kannst ändern ein Umkodieren nicht viel an den zentralen Ergebnissen deines Modells. Ich hatte gedacht, dass dir hierdurch eine Interpretation der Modelle einfacher fallen könnte.
klaus82 hat geschrieben:Welches ist denn jetzt das sauberste/brauchbarste Modell?
Prinzipiell könntest du vor der Modellierung schauen, wie die wie die Kategorien deiner abhängigen Variable in ihren Häufigkeiten verteilt sind und hiervon abhängig den entsprechenden Link wählen. An dieser Stelle muss ich erwähnen, dass dies im allgemeinen keine sonderlich gute Methode ist. Es wäre besser die Wahl des Links, aus einer geeigneten Kontrollstichprobe abzuleiten.
Sprechen die Informationen zur Modellanpassung für das Modell, so ist das erstmal "gut" und diesbezüglich gibt es auch daran "nichts zu rütteln".
Weiterhin kannst du die Tendenzen der Wirkungsrichtung (bzgl. der Kategorien der abhängigen Variablen) der Kategorien der erklärenden Variablen untersuchen. Hierbei würde ich aber Abstand von einem Vergleich der Einflüsse erklärender Kategorien nehmen! Also z. B. würde ich keine Vergleiche der Art "Kategorie 1 wirkt stärker auf höhere Kategorien als es Kateorie 2 tut" durchführen.
Ebenso können die Kategorien auf eine Signifikanz untersucht werden.
Abschließend ist mir aufgefallen, dass sich die Daten in der Zusammenfassung der Fallverarbeitung in den 3 Modellen unterscheiden. Zum Beispiel: Liegen im ersten Modell 19 fehlende Fälle vor. In den anderen beiden sind es hingegen jeweils 12. Weiterhin liegen beispielsweise im ersten Modell 20 Fälle mit einer mittleren gesundheitlichen Beeiträchtigung und bei den beiden anderen Modellen 25 solcher Fälle vor.
Gruß

