
Hallo Zusammen,
mir ist nicht klar was mit dem e bei der Regression passiert. Wird das e in der einfachen (und multiplen) Regressionsformel (y = a +b*x + e) auf 1 oder auf 0 gestellt? Viele Lehrbücher führen zwar einmal das e an, wird aber später nicht mehr berücksichtigt.
Vielen Dank und Grüße
Flow
e in der Regressionsformel
Thema bewerten:  • 2 Beiträge
• Seite 1 von 1
• 2 Beiträge
• Seite 1 von 1
e in der Regressionsformel
![]() von Flow » Mo 8. Jul 2013, 15:45
von Flow » Mo 8. Jul 2013, 15:45
- Flow
- Power-User

- Beiträge: 61
- Registriert: Mi 31. Aug 2011, 14:22
- Danke gegeben: 4
- Danke bekommen: 0 mal in 0 Post
Re: e in der Regressionsformel
![]() von daniel » Mo 8. Jul 2013, 23:07
von daniel » Mo 8. Jul 2013, 23:07
Zunächst muss zwischen dem theoretischen Fehler (meist  , kann aber auch e sein) und den empirischen Residuen (meist e oder
, kann aber auch e sein) und den empirischen Residuen (meist e oder  ) unterschieden werden.
) unterschieden werden.
Die empirischen Residuen sind schlicht die (tatsächlich berechenbaren) Abweichungen der vorhergesagten Werten von den beobachteten Werten.
Für die theoretischen Fehler wird eine (Normal)Verteilung mit Mittelwert 0 und Varianz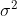 angenommen. Sind diese Annahmen verletzt, kommt es zu Verzerrungen bei der Schätzung der Koeffizienten und/oder Standardfehler.
angenommen. Sind diese Annahmen verletzt, kommt es zu Verzerrungen bei der Schätzung der Koeffizienten und/oder Standardfehler.
Interessenat wird das bei der "soziologischen" Herleitung (oder der "light" Variante der Herleitung) des binär logisitischen Modells (etwa hier: http://www.uni-bamberg.de/fileadmin/uni ... g-BBES.pdf). Dort verschwindet der Fehler nämlich in der Tat auf wundersame Art und Weise (die mir auch noch niemand plausibel erklären konnte) und es ist de facto unmöglich das (eigentlich identische) probit Modell auf diese Weise herzuleiten.
Du stellst hier eine wichtige Frage. Versuch die Antwort zu verinnerlichen, und merk Dir einfach schon mal vorab, dass die Annahmen über den Fehler den Hauptunterschied zwischen vielen Regressionsmodellen ausmacht.
Die empirischen Residuen sind schlicht die (tatsächlich berechenbaren) Abweichungen der vorhergesagten Werten von den beobachteten Werten.
Für die theoretischen Fehler wird eine (Normal)Verteilung mit Mittelwert 0 und Varianz
Interessenat wird das
Du stellst hier eine wichtige Frage. Versuch die Antwort zu verinnerlichen, und merk Dir einfach schon mal vorab, dass die Annahmen über den Fehler den Hauptunterschied zwischen vielen Regressionsmodellen ausmacht.
Stata is an invented word, not an acronym, and should not appear with all letters capitalized: please write “Stata”, not “STATA”.
- daniel
- Inventar

- Beiträge: 739
- Registriert: Mo 6. Jun 2011, 13:23
- Danke gegeben: 0
- Danke bekommen: 169 mal in 161 Posts
Thema bewerten: • 2 Beiträge
• Seite 1 von 1
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 2 Gäste